原文:BUILDING A MOVIE RECOMMENDATION ENGINE WITH R
常见的机器学习课程(比如Udacity Course)建议的第一个小项目通常就是推荐引擎,因此我打算做一个电影的推荐引擎。在这篇文章中,我将尝试应用基于内容过滤方法及协同过滤方法来搭建一个基本的电影推荐引擎。
数据集
我所使用的数据集来自 MovieLens,数据可以从此处下载。为了使这个推荐引擎尽可能的简单,我使用了最小的数据集 (ml-latest-small.zip) ——来自于706个用户对8,570部电影的100,000个电影评分。
|
|

|
|
基于内容过滤方法
如方法名称所表达的相同,基于内容过滤方法包括分析与用户相作用的条目,并给出在内容上与该条目相似的推荐结果。在这里,内容指的是描述条目的一系列属性或特征。
对于一个电影推荐引擎来说,基于内容的方法将会推荐在电影流派、演员、导演、出品年份等特征方面最相似的电影。这里假设了用户倾向于某一种固定类型的物品,因此我们试图推荐给该用户的,是与他已经表示过喜爱的物品相类似的物品。此外,我们的目的是给予用户除他已观看过的电影之外的替代品。
在这篇文章中 ,我将搭建一个最基本的基于内容的推荐引擎,只考虑电影流派一个属性。在更复杂的推荐引擎中,应使用多种属性,并对更重要的属性给予更高的权重。通过TF-IDF算法(Term Frequency–Inverse Document Frequency algorithm)可以实现上述思路。对于搭建一个简单的基于内容的推荐引擎来说,用户资料对于确定该用户的偏好趋势是必不可少的,并且可以通过用户的偏好及观看行为来构建。
数据预处理
为了获取电影特征矩阵,电影数据集中用竖线分割的流派应先被分离出来。data.table 包中有一个 tstrsplit() 函数可以很好的应用于分离字符串。
|
|
这将使我们获得一个如下所示的矩阵,基本上与 movie$genres 相同,但每一种 genre 被分离到不同的列中了。

然后构建一个将每一种电影流派作为列的矩阵,并标记出每一种电影流派是否在每一部电影中。
|
|
我们现在获得了电影流派的矩阵。每一列表示每一种不同的电影流派,每一行是每一部不同的电影。数据集现在如下表所示。我们有18个不同的类型及8570部不同的电影。

现在,我们需要构建一个用户资料矩阵。使用 reshape2 中的 dcast() 函数可以很轻松地做到这点。为了简单起见,我首先将评分转换为一个二元格式,评分在4~5之间的映射为1,表示喜欢;而评分在3及3以下的映射为-1,表示不喜欢。
|
|
目前二元制评分的数据集如下所示:

为了将这个二元评分矩阵转换为我们需要的格式,我使用了 reshape2 包中的 dcast() 函数,将数据从长数据的格式转换为宽数据的格式,这个操作也会产生许多 NA ,因为并不是每个用户对每个电影都进行过打分。我将 NA 都替换成了0.
|
|
现在我们将二元评分矩阵转换成了正确的格式。该矩阵由8552行,分别代表每一部电影ID;706列,分别表示每一个用户ID. 该矩阵大概如下所示:

为了构建简单的用户资料矩阵,我计算了电影流派矩阵和二元评分矩阵的数量积。在进行点乘运算之前,需要注意的是电影数据集由8570部电影组成,但评分数据集只有8552部电影。为解决该问题,我将未出现在评分矩阵中的电影从电影流派矩阵中剔除出去了。
|
|
现在我们可以计算电影流派矩阵和评分矩阵的数量积,从而获取用户资料了。
|
|
用户资料展示了每个用户对于各电影流派的整体倾向。列是用户ID,正值表示该用户对特定流派的偏好。之后将数值简化为二元矩阵——正值映射为1,表示喜欢;负值映射为0,表示不喜欢。
现在我们有了用户资料数据,之后的分析有两种方法可供选择。
- 基于物品描述(电影流派)预测用户是否会喜欢该物品。可以通过预测用户对电影评分得到。
- 假设用户喜欢的物品都是同一类型的,而用户资料表示了他对商品特性的偏好,那么根据用户资料显示所推断出来的与其偏好最相似的就是需要推荐给该用户的电影。
我选择了第二种方式,并使用 Jaccard 距离来衡量用户资料和电影流派矩阵之间的相似度。之所以选择 Jaccard 距离是因为它比较适用于二元数据的相似度衡量。
我使用了 proxy 包中的 dist() 函数来计算 Jaccard 距离。但是,该函数计算的是同一个矩阵不同行之间的距离。因此我需要对每一个用户都将电影流派矩阵和他对应的用户资料矩阵合并为一个矩阵,然后获取与每个用户的最小距离。在我的本地环境下,这项计算花费了不少时间。
为了简单起见,下面只展示对数据集中第一个用户的处理方式。
|
|
现在我们成功生成了对数据集中第一个用户的一些推荐建议。你可以对数据集中每一个用户进行这样的循环操作,直到获得给所有用户的推荐建议。
让我们来看一下结果。
下面所示的是对 User 1建立的用户资料。User 1感兴趣的电影流派包括:儿童,纪录,奇幻,恐怖,音乐,战争。

我们向 User 1推荐的电影:

这些电影的相似度评分为0.5.我们可以推断出来ID为4291和65585的电影之所以评分较高是因为它们分别只标记了两种流派。User 1只对喜剧感兴趣,而且对犯罪类型和爱情类型的影片不感兴趣,因此这些看起来不像是有质量的推荐结果。解决这种问题的一个方法就是给每一种流派设定一个等权重。通过将流派矩阵中的每一个值除以对应电影所标记的流派数目的平方根就可以达到。比如对于ID为2015的电影,应除以sqrt(3),而对于ID为4291的电影,则应除以sqrt(2).将每一种流派基于相同权重之后,应该可以提高推荐的质量。
现在我们完成了一个简单的基于内容的推荐系统,让我们来对比一下这种方法的优缺点。
优点:基于内容的推荐系统不需要大量的用户数据。只需要物品数据就可以向用户提供推荐结果。而且,由于你的推荐系统不必依赖于大量的用户数据,因此可以就算是你的第一名用户,只要可以获得足够的数据来构建他的用户资料,就可以给他相应的推荐建议。
缺点:这种方法要求物品数据是具有合理分布的。如果你的电影中80%都是动作片,那么通过基于内容的推荐系统就无法得到有效的推荐结果。此外,由此方法所得到的推荐结果通常是与用户有过交互的物品的直接替代品,而非互补品。互补品通常可以通过协同技术获得,下一部分中会有提到。
现在我们进行下一种方法!
基于用户的协同过滤方法
基于用户的协同过滤方法将用户按照之前使用的行为或者其偏好进行分组,然后在同一组中的相似用户浏览或喜欢过的物品推荐给该用户。用外行人的话来说,如果User 1喜欢电影A、B、C,而且如果 User 2喜欢电影 A 和 B,那么就可以将电影 C 作为推荐建议推荐给 User 2. 基于用户的协同过滤方法模仿了实际生活中的口碑推荐方法。
在这篇文章中,我将使用基于用户的协同过滤方法对使用 R 中 recommenderlab 包的用户生成一个生成一个 top-10 推荐列表。使用 recommenderlab 包可以很简单的实施目前一些比较流行的协同过滤算法。
数据预处理
我们需要一个评分矩阵来通过 recommenderlab 包建立推荐模型。我们再次通过使用 reshapes2 包中的 dcast() 函数完成此步骤。
|
|
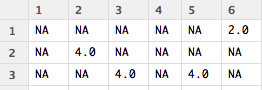
下面是这个706×8552评分矩阵的预览。
建立推荐模型
基于用户的协同过滤推荐模型通过评分矩阵和 recommenderlab 建立,有以下参数:
Method: UBCF
Similarity Calculation Method: Cosine Similarity
Nearest Neighbors: 30
预测的用户对物品的评分结果将由与其最近邻的5个条目中推导得出。获得了预测的物品评分之后,前10个预测评分最高的物品将返回为推荐建议。
数据标准化:
|
|
我们轻而易举地获得了 User 1 的 top-10 结果!推荐给 User 1 的电影如下所示。

recommenderlab 包还提供了可以很简单地对我们的模型进行评估的方法。
|
|
top-N 推荐系统的评价结果:

我们来分析一下基于用户的协同过滤方法的优缺点。
优点:基于用户的协同过滤方法给予用户的推荐是他们有过交互的物品的互补品。这种推荐结果可能比基于内容的推荐系统所得出的结果更有力,因为用户不一定会想看他们刚刚或早就看过的电影的替代品。
缺点:基于用户的协同过滤方法是一种基于记忆的协同过滤,使用了数据库中所有的用户数据来建立推荐结果。比较数据库中每个用户的成对相关性的操作是相对不可扩展的。如果有上百万的用户的话,相应的计算量将耗费相当长的时间。通过使用一些数据降维方法,比如主成分分析法,或者使用基于模型的算法,可以应对这种问题。此外,基于用户的协同过滤方法依赖于过于的用户选择来推断未来的推荐。这就意味着我们假设了用户的口味和偏好在时间维度上多多少少保持一个恒定不变的状态,但这种假设不一定成立,并且使得想要在线下预计算用户相似度较为困难。
来源: coursera, recommenderlab